1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
'''
Blog:https://www.imortal.icu
Author:imortal
'''
import re
import sys
import time
import requests
import threading
sem=threading.Semaphore(100)
url_re = re.compile(r'<a href="(.*?)" target="_blank"')
head = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'BAIDUID=4E1F48863DE6180CB275FC38826CD741:FG=1; BIDUPSID=4E1F48863DE6180C0425C90DEB64DA88; PSTM=1657768645; BD_UPN=13314752; ZFY=A7LYxpn3VZCuGnOtwfGfP1T1OYErt87SDFQGsLE6aaw:C; COOKIE_SESSION=129306_0_4_4_1_4_1_0_4_4_0_0_0_0_2_0_1658385541_0_1658385539%7C5%230_0_1658385539%7C1; baikeVisitId=51e786eb-5497-4b5b-bd36-485d969cc770; Hm_lvt_aec699bb6442ba076c8981c6dc490771=1658256230; B64_BOT=1; H_PS_645EC=cd791WcJIjH2j2IzGRQKOe%2BzrQxF2yOtETeX3vsZq40XJjzyhhFRwEhI24C3QYesfKDN; BA_HECTOR=242h8kag8la42l80242kle1d1hdht4417; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; ab_sr=1.0.1_ZmExYTE0Zjg5ODJlYjM2Y2EzOTY5N2ViZWZjYTA5Y2E5MzU2ZmYxNTdlM2ZkMGUyODNlYzE3MWE3OGU1MTgyZGM3YTllNjBhMjNhZjJiMDA5MjIxMTQwNzRiNWVmMjY3MDM4OTdiYzM3ZDQxZmJmYzhhM2RmMWY5MTVmMWNjOTgyMWUwNDFhNjlhZTRkNWI4ZGIzYTA2MDM4YTZlYjMwZA==; BD_HOME=1; H_PS_PSSID=36547_36756_36255_36726_36455_36413_36846_36452_36690_36165_36816_36570_36776_36773_36637_36746_36760_36768_36766_26350_36861',
'Host': 'www.baidu.com',
'Referer': 'https://www.baidu.com/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.62',
'sec-ch-ua': '" Not;A Brand";v="99", "Microsoft Edge";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
proxies={
'http':'127.0.0.1:8080','https':'127.0.0.1:8080'
}
def result_url(target):
result = open('url.txt', 'a+')
with open('url.txt') as f:
if target not in f.read():
result.write(target +'\n')
result.close()
def result_domain(target):
target = 'http://' + target.split('/')[2]
result = open('domain.txt', 'a+')
with open('domain.txt') as f:
if target not in f.read():
result.write(target +'\n')
result.close()
def spider(url):
with sem:
try:
req = requests.get(url=url,headers=head,timeout=5)
urls = url_re.findall(req.text)
for url in urls:
req = requests.get(url=url,timeout=5)
target = req.url
if 'baidu' not in target and '51cto' not in target and 'csdn' not in target and 'jiameng' not in target:
print(target)
result_url(target)
result_domain(target)
except:
pass
time.sleep(0.1)
if __name__ == '__main__':
if len(sys.argv)!= 2:
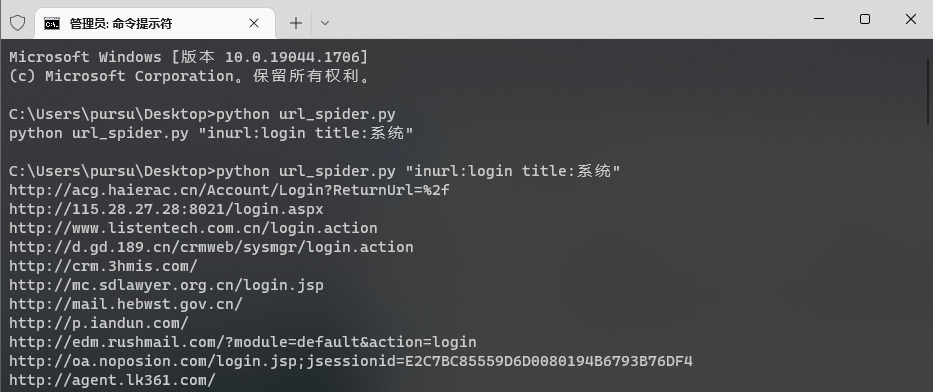
print('python url_spider.py "inurl:login title:系统"')
sys.exit(-1)
else:
keyword = sys.argv[1]
for i in range(0,750,50):
url_start = 'https://www.baidu.com/s?wd=' + keyword + '&rn=50&pn='
url = url_start+str(i)
t=threading.Thread(target=spider,args=(url,))
t.start()
|